Research Interest
Machine Learning in CyberSecurity: I am interested in developing unsupervised models to automate intrusion detection.
I am also interested in building more optimized federated learning models that can update novel intrusions in real time to their peer clients
and alleviate the privacy issue that comes with analyzing network logs of devices.
Recently, I have also been investing an ample amount of time in understanding to create cyber-attacks with generative models that mimic the pattern of the original cyber-attacks,
evading state-of-the-art deep learning-based IDS.
Security and Privacy of Machine Learning: I am interested in analyzing machine learning models from an adversarial lens,
developing possible attacks and approach to defend them. These attacks are but not limited to Data Reconstruction, Gradient Poisoning, and Data poisoning.
My additional interest also lies in Federated Machine Learning.
My research story: I started my research journey in the second year of my college, where I published my first paper.
Since then, I have been actively involved in research. Most of my research papers are an outcome of independent research with very little supervision from a professor.
I believe that self-motivation, persistence, and a strong desire for scientific contribution are key factors to succeed in research.
As a part of my research journey, I have been fortunate to mentor various students on research. Some of them are:
1. Prajwal Gupta -> Research Intern at SAI Lab -> Grad student at Northeastern University.
2. Aarushi Sethi: Research Intern at SAI Lab -> Research Intern at NTU Singapore -> Grad student at UT Dallas.
3. Himashree Deka: NIT Kurukshetra -> PhD at IIT Guwahati.
4. Mavneet Kaur: Research Intern at SAI Lab -> Grad student at Stony Brook University
Ongoing Research
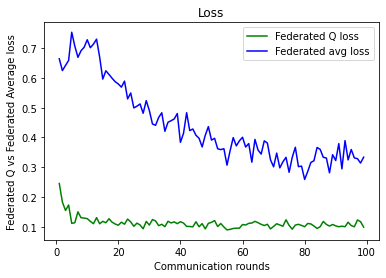
Faster Convergence through Weight Re-parameterization.
Paper under draft
Github Link
This research project modifies the widely used federated averaging algorithm using the concept of weighted average. The Federated averaging algorithm gives equal weights to the clients during aggregation if we are detecting cyber-attacks with FL. However, in real-world scenarios, malicious traffic is not uniformly distributed among all clients. Hence giving them equal weights makes convergence very slow. In this research project, we have developed a modified version of the fed-avg algorithm, which dynamically assigns distinct weights to each client during aggregation. These dynamic weights are determined with the help of malicious traffic present at each node. The higher the number of malicious traffic, the higher the weight of the client is. Our experimentation has shown that the re-parameterization of weights using the weighted-average concept makes convergence much faster than simple-average. This approach benefits the peer nodes in a distributed setting to learn the patterns of cyber-attacks happening on other peer nodes in a few communication rounds.
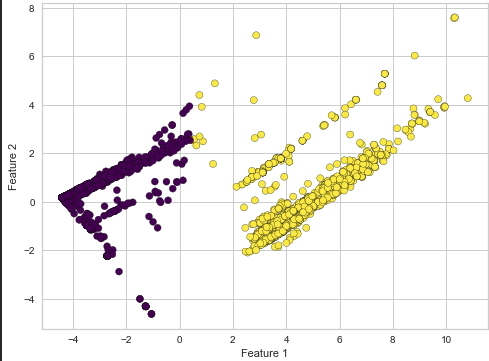
Semi-Supervised Learning for Labelling an Unlabelled Dataset with Loss Function
Most of the network traffic that contains benign and malicious traffic is unlabelled in nature. One of the ways to label this dataset is semi-supervised learning, but semi-supervised learning comes with errors in labeling. This project aims to define a loss function for semi-supervised learning that can calculate loss while detecting labels and optimize its labeling process.
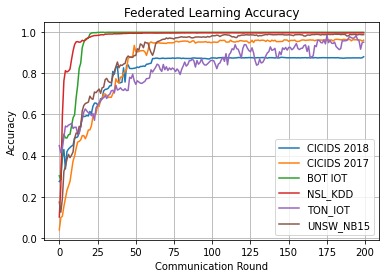
Federated Learning in Heterogenous IoT Network with Constant Feature Space.
Paper under draft
Github Link